


那这样一个混合模型有什么好处呢?当用户输入一个问题时,会进行意图识别,优先匹配擅长这块领域的大模型进行回答。
目前来看并没有一个大模型敢说自己在各个领域全方面领先,哪怕强如 GPT-4O 和 Claude3.5 也不行。而这样集各家之所长的“大模型”,可以说基本全方面达到最优,集成了国内大部分头部模型。
这其中最关键的问题就是:怎么知道哪个大模型在哪块领域擅长?于是 360 用自己过去积累的用户真实数据,找了几千万条问题,划分成 4000 个类别,对这些模型进行测试。

包括写作、代码生成、翻译、比一比、诗词赏析、知识问答等,决策出各个分类下的最强大模型。
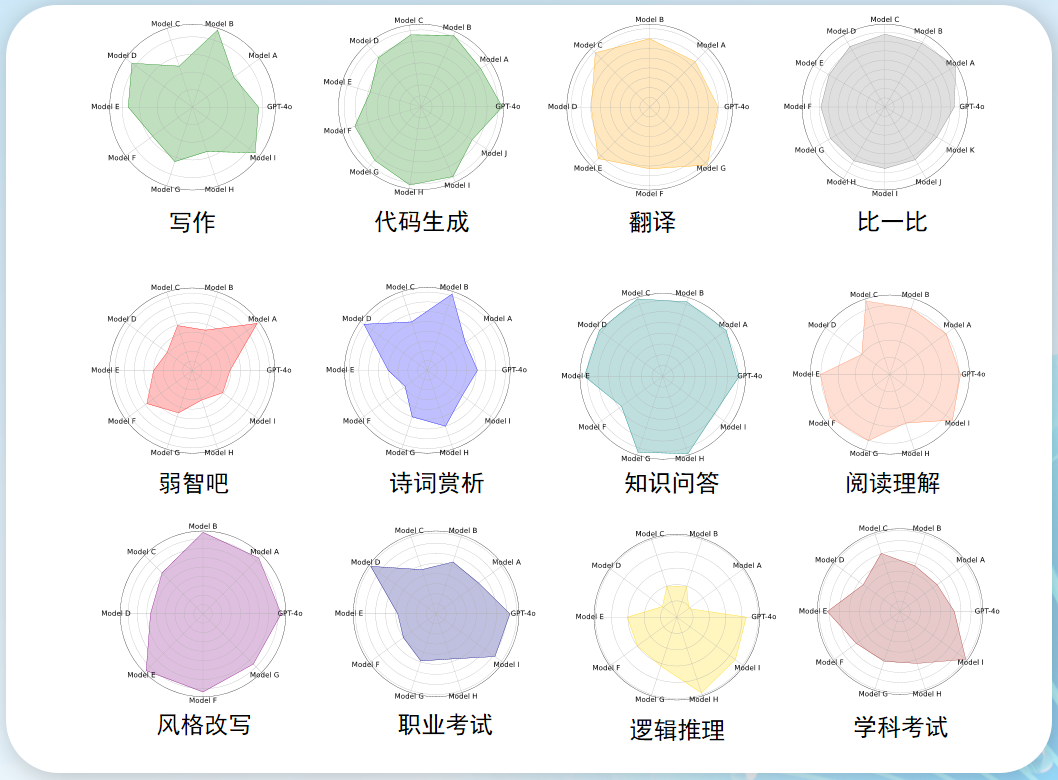
最终它得出了各个模型擅长的领域如下:
-
360 智脑:擅长搜索、总结、思维导图,生成速度超快; -
豆包:擅长创意写作、逻辑推理、知识问答等方向; -
DeepSeek:对代码和图表具有强大的理解能力; -
MiniMax:适合沉浸式角色扮演体验,引入超多虚拟角色; -
通义千问:以电商、法律垂类的知识库和翻译能力著称; -
Kimi:20W字超长记忆,擅长各种专业领域知识; -
零一万物:办公首选,适合会议纪要、周报等场景; -
文心一言:适合内容创作、对比判断类知识问答领域; -
讯飞星火:逻辑推理、翻译能力突出,擅长教育方向; -
商量-商汤:擅长医疗、编程等专业的垂直方向; -
智谱清言:擅长多模态场景,模型推理训练等; -
百小应:通用医疗增强大模型,AI医疗向专家;

相当于普通人的测试结果来说,360 测量得出的结果肯定更加准确。
有一个场景,之前单问某个模型,回答一直很傻逼。就是让它生成一个笑话,看看单个模型回答的结果:
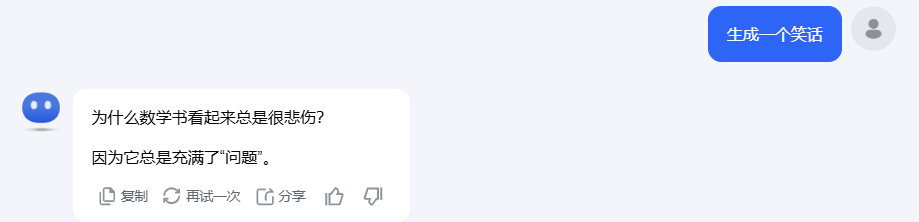
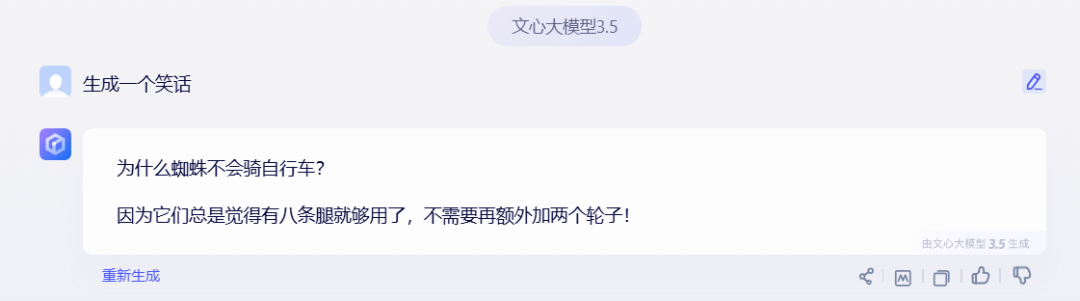
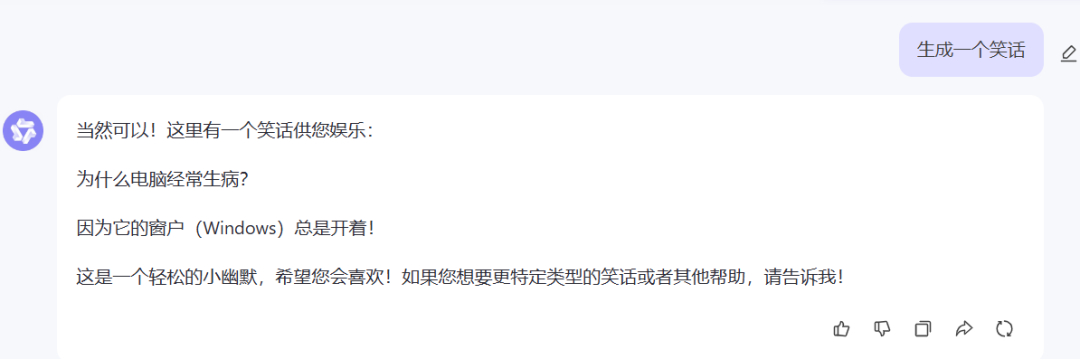
看看 Kimi、文心一言、通义千问生成的笑话,是真的不好笑啊,属实有点尬。
而通过混合模型生成的效果明显就好上不少,看生成结果里显示是调用的豆包模型。
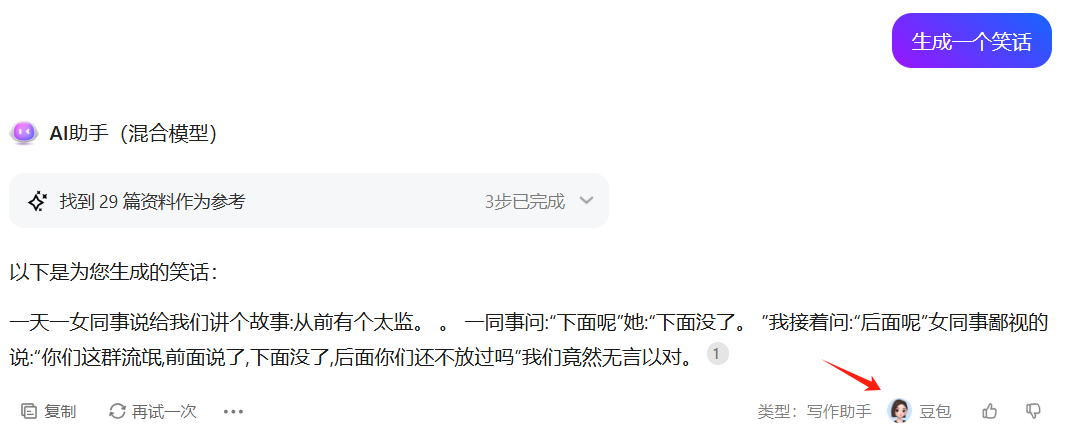
这就是混合模型的强大,生成的结果起码在国内应该是最优的,而对于使用者来说可以将它只当做是单个模型使用。
当然如果你想自己指定某个模型回答也是可以的,在这个网页上你可以随意切换模型,不需要登录到各个模型的官网上。
现在体验比较不好的一点是:不支持文件上传。因为 CoE 混合模型本身不具备文件读取的能力,就无法识别要调用哪个模型,这个需要 360 进一步优化了。
