

编者按:我们今天为大家带来的这篇文章,作者的观点是文本嵌入向量并非我们想象中的安全载体,在某些条件下,通过适当的技术手段可以高精度地还原出原始文本内容。
作者在本文介绍了其开发的 vec2text 方法 —— 一种基于迭代优化的文本反演技术,能够以 92% 的精确率还原 32 个词元的文本序列,BLEU 分数高达 97 分。这一技术为企业在部署 AI 系统时的数据安全策略敲响了警钟。
本文系原作者观点,Baihai IDP 仅进行编译分享
作者 | Jack Morris
编译 | 岳扬

向量数据库的崛起
近年来,随着生成式 AI 的迅猛发展,众多企业正争相将 AI 技术融入其业务中。其中一个最普遍的做法,是构建能够基于文档数据库中的信息来回答问题的 AI 系统。解决此类问题的主流方案大多基于一项关键技术:检索增强生成(Retrieval Augmented Generation, RAG)。
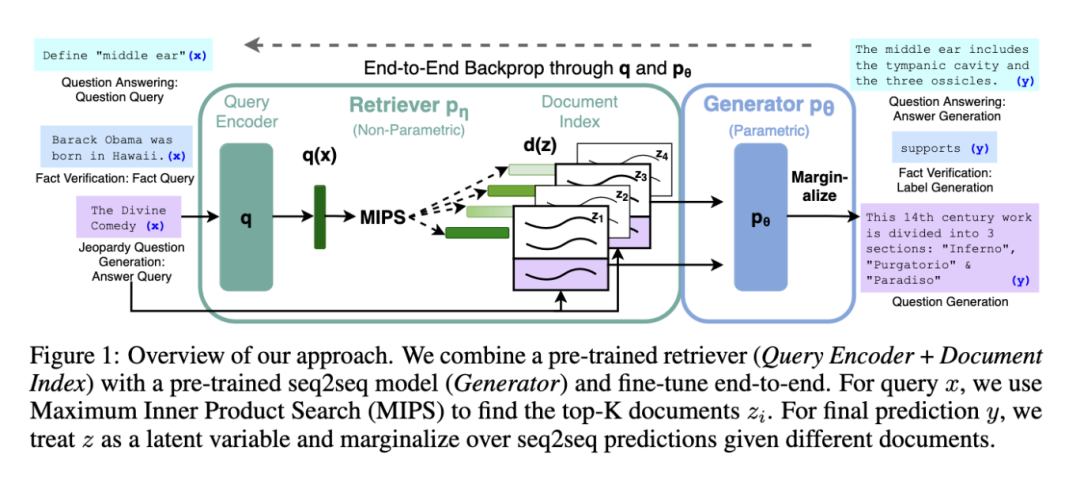
RAG 系统概览。来源:”Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”[1]
这正是当下许多人开启 AI 应用之旅所采用的一种既经济又快捷的方案:将大量文档存储于数据库中,让 AI 根据给定的输入检索最相关的文档,然后依据检索到的文档信息生成对输入的响应。
这些 RAG 系统通过使用“嵌入向量”(embeddings)—— 即由嵌入模型(embedding model)生成的文档向量表征 —— 来确定文档的相关性。这些嵌入向量本质上是通过数学方式来表征语义关联性,因此,与搜索需求相关的文档,在嵌入向量空间中应具有较高的向量相似度(vector similarity)。
RAG 的普及推动了向量数据库这一新型数据库的崛起,这种数据库专为存储和搜索大量嵌入向量而设计。一些初创公司已经获得了数亿美元的资金[2-5],它们声称可以通过简化嵌入搜索过程(embedding search)来促进 RAG 的发展。而 RAG 的有效性,正是大量新兴应用将文本转化为向量并存储于这些向量数据库的原因所在。
嵌入向量难以解读
那么文本嵌入向量中存储的究竟是什么?除了必须体现语义相似性(semantic similarity)这一要求外,对于给定文本输入应分配何种嵌入向量并无任何约束。嵌入向量中的数值具有不确定性,其具体取值取决于模型的初始化状态。我们或许能解读不同嵌入向量之间的关联性,但永远无法理解单个嵌入向量的具体数值含义。

一个神经嵌入模型(浅蓝色)接收文本输入并生成用于搜索的嵌入向量
现在设想你是一名软件工程师,正为公司搭建 RAG 系统。你决定将向量存储在向量数据库中。此时你发现,该数据库实际存储的是嵌入向量,而非原始文本数据。数据库中充斥着大量看似随机的数字,它们虽然代表着文本数据,但系统实际上从未真正“接触”过任何原始文本。
你清楚这些文本对应的是受公司隐私政策保护的客户文档。但严格来说你从未将任何文本传输至外部;传输的始终是嵌入向量,这对你而言仅是一组随机数字。
如果有人黑进数据库并获取所有文本嵌入向量 —— 这是否会造成严重后果?如果服务提供商想将您的数据售卖给广告商 —— 他们能否做到?这两种场景的核心在于:攻击者能否获取嵌入向量并通过某种方式反推出原始文本。
从文本到嵌入向量…再回到文本
从嵌入向量中复原原始文本的问题,正是我们在论文《Text Embeddings Reveal As Much as Text》(EMNLP 2023)[6] 中要解决的问题。嵌入向量是一种安全的信息存储和通信载体吗?简而言之:能否从输出的嵌入向量中还原输入文本?
在深入探讨具体解决方案之前,让我们进一步剖析该问题。文本嵌入向量(text embeddings)本质上是神经网络的输出结果 —— 是对输入数据实施非线性函数运算与序列化矩阵乘法后的产物。在传统的文本处理神经网络中,字符串输入被拆分为若干词元向量,这些向量会反复经历非线性函数运算。在模型的输出层,所有词元将被聚合为单个嵌入向量。
信号处理(signal processing)领域有一条著名的规则叫数据处理不等式(data processing inequality),它表明:任何函数都无法为输入数据增加信息量,它们仅能维持或削减既有信息量。尽管业界普遍认为神经网络远离输入层的隐藏层会逐步构建更高级的特征表示,但实际上,它们并没有添加任何输入数据中原本不存在的信息。
此外,非线性层肯定会造成一些信息损失。现代神经网络中“无处不在”的一个非线性层便是 ReLU 函数 —— 其核心运算逻辑是将所有负输入值归零。当 ReLU 函数在典型文本嵌入模型的许多模型层中被反复应用后,就不可能保留输入的所有信息。
其他领域的信息反演问题
类似问题在计算机视觉领域也广受关注。多项研究结果表明,来自图像模型的深度表征(本质上是嵌入向量)可以在一定程度上还原输入的图像。早期的一项研究(Dosovitskiy, 2016)[7]表明,可以从深度卷积神经网络(CNN)的特征输出中还原图像。研究者通过深度卷积神经网络(CNN)提取的高层次特征信息,可以逆向重构出输入图像的近似版本,尽管重构的图像不够清晰,但仍保留了与原图像相似的主要特征和结构。
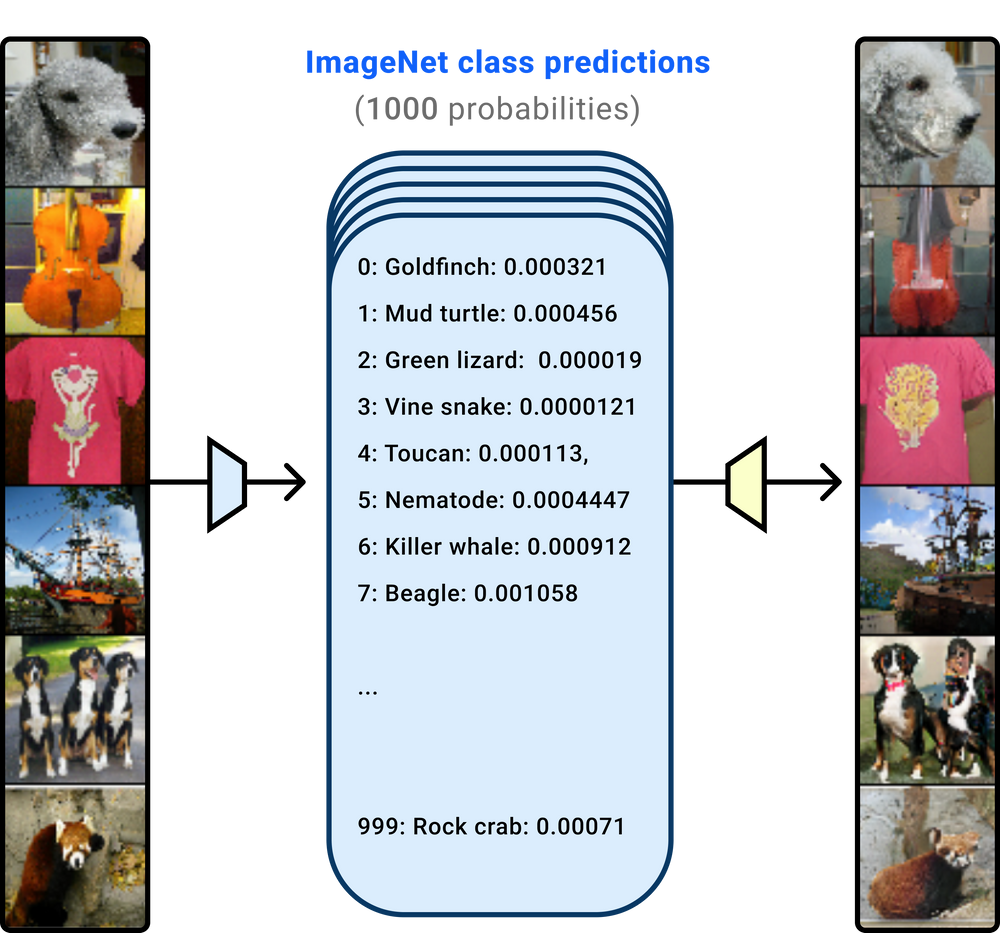
在计算机视觉领域,反演模型(inversion models)(图中使用黄色标注)在仅给定 ImageNet 分类器输出的 1000 个类别概率值(其中绝大多数接近 0)的情况下,成功重建了图像。(此图来自《Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers》[8])
自 2016 年以来,人们不断改进图像嵌入反演技术:已开发出具有更高精度的反演模型[8-10],并被证明适用于更多场景[11]。令人惊讶的是,某些研究表明,仅凭 ImageNet 分类器的输出(1000 个类别的概率值)也可以实现图像的反演。
vec2text 的实现之旅
既然图像表征能够实现反演(inversion),那么文本表征为何不可?让我们来思考一个简化了的研究场景下的文本嵌入还原问题。在此实验中,我们将文本输入限制为 32 个词元(tokens)(约 25 个单词,相当于一条长度适中的句子),并将这些文本全部嵌入(embed)到由 768 个浮点数构成的向量中。若以 32 位精度(32-bit precision)计算,这些嵌入向量占用 32 * 768 = 24,576 比特(bits)即约 3 千字节(3 kilobytes)。
用海量比特表达寥寥数词。 在这种情况下,你认为我们能否完美地重建原始文本呢?
首先,我们需要定义一个衡量标准,用来评估我们完成任务的效果。一个直观的指标是”精确匹配率”(exact match),即反演后得到完全一致输入文本的频率。现有的反演方法在该指标上都没有取得任何成功,可见其标准之严苛。因此我们或许应从更平缓的指标起步 —— 衡量复原文本与输入文本的相似度。为此我们将采用 BLEU 分数(BLEU score),你可将其简单理解为复原文本与原文的相似程度。
定义好评估指标后,我们将提出基于该指标的验证方案。作为初步尝试,我们可将反演问题转化为传统机器学习任务:收集海量的嵌入向量-文本配对数据集(embedding-text pairs),训练一个以嵌入向量为输入、输出对应文本的模型。
这正是我们的实践方案:我们构建了一个以嵌入向量为输入的 Transformer 模型,并采用经典语言建模方法对输出文本进行训练。通过该初步方案,我们获得了一个 BLEU 分数约为 30/100 的模型。实际表现中,该模型能推测输入文本的主题并捕捉部分词汇,但会打乱词汇顺序且多数词汇预测错误。其精确匹配率趋近于零。事实证明:要求模型通过单次前向传播(forward pass)逆向还原另一模型的输出是极其困难的(其他复杂文本生成任务亦如此,例如生成严格符合十四行诗押韵结构(perfect sonnet form)或需要同时满足多重约束条件的文本)。
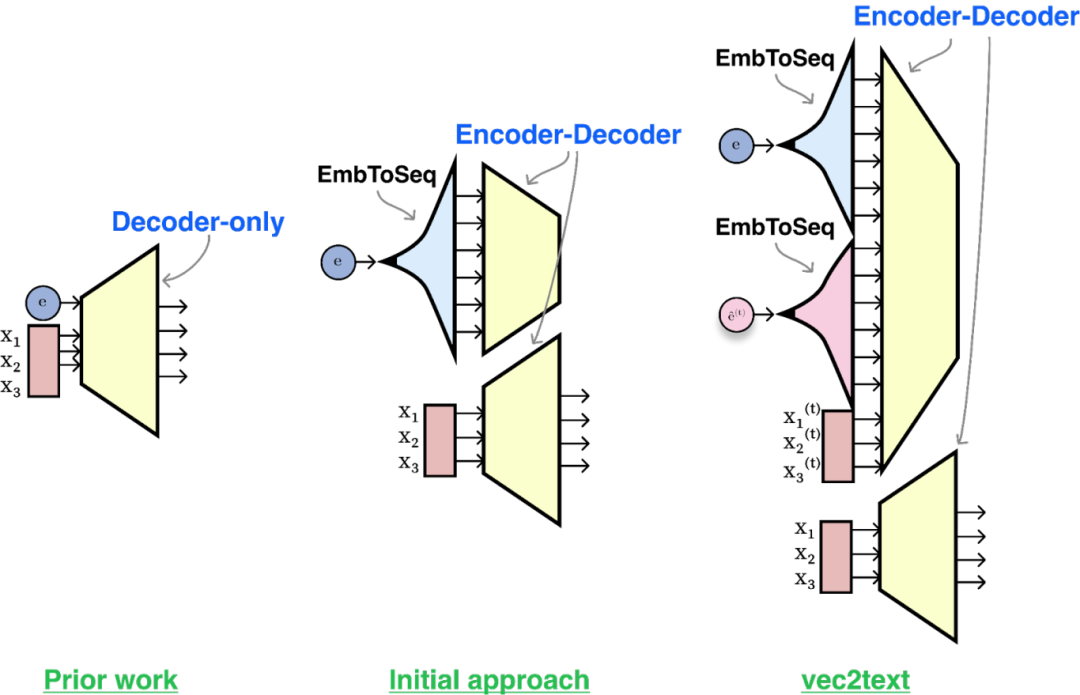
所考察架构概述。先前工作(左图)采用仅解码器架构(decoder-only architecture),并将嵌入向量作为前缀输入(prefix)。我们最初训练的编码器-解码器模型(中图)在编码器端(encoder-side)对升维处理的语句嵌入向量进行条件化处理。在我们的最终方案(右图)中,除了升维处理后的“假设”嵌入向量外,还额外引入了“假设”文本作为辅助输入。
在训练初始模型后,我们发现了一个有趣现象。另一种衡量模型输出质量的方法是:对生成的文本(我们称之为“hypothesis(假设)”)进行重嵌入处理(re-embedding),并测量该嵌入向量与真实嵌入的相似度。使用我们模型生成的文本来计算时,观测到余弦相似度(cosine similarity)高达 0.97。这意味着我们能生成在嵌入空间中逼近真实文本(ground-truth text)但又不完全相同的文本。
(插叙:如果情况并非如此呢?也就是说,如果嵌入模型将错误的生成文本与原始文本映射为完全相同的向量表示,则该嵌入器(embedder)将具有信息有损性(lossy),导致多个输入被映射至相同的输出。此时,问题就会无解了 —— 因为当多个不同文本序列对应同一个嵌入向量时,系统根本无法追溯原始输入。但在实际实验中从未观测到此类嵌入冲突(collisions)。)
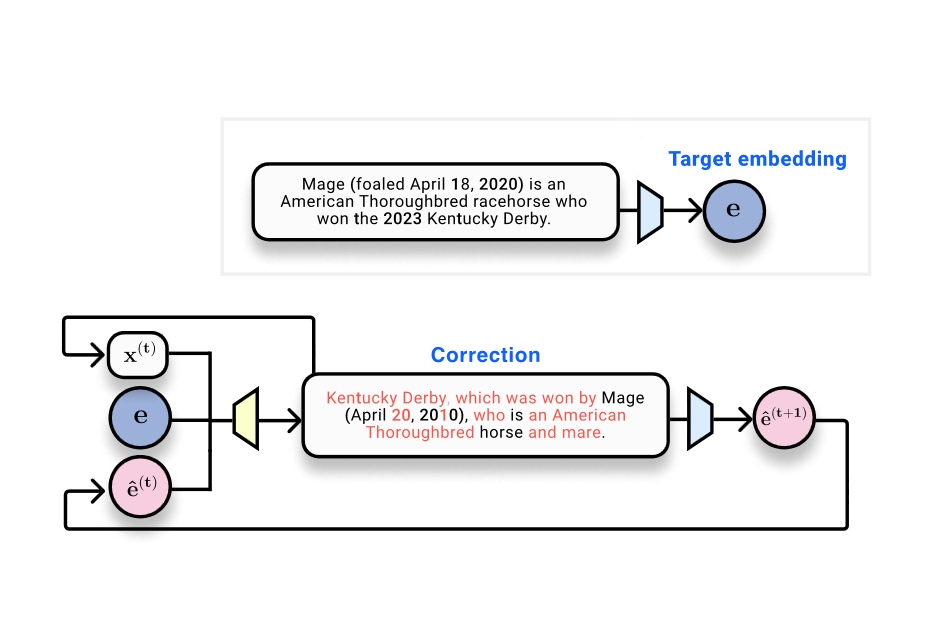
生成文本与真实文本具有不同嵌入向量的观察,启发了我们采用类优化方法(optimization-like approach)实现嵌入反演。给定目标嵌入向量(即需要获得的真实嵌入)和当前“假设”文本及其嵌入(当前状态),可训练一个校正器模型(corrector model):该模型以输出比原假设文本更接近真实嵌入的内容为训练目标。
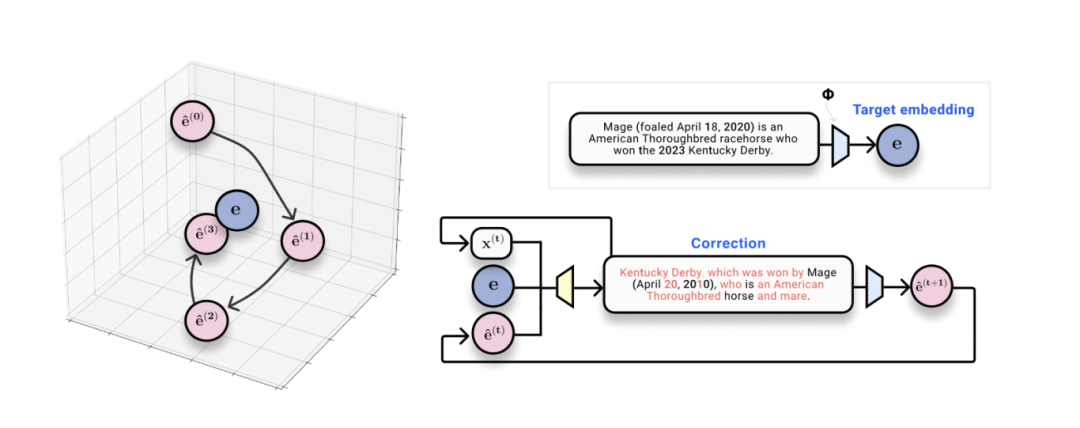
Vec2Text 方法概述。在获得目标嵌入向量 e(蓝色)和调用嵌入模型 φ(蓝色模型)的查询权限后,系统通过迭代生成(黄色模型)假设嵌入 ê(粉色)来逼近目标。
我们的目标现已明确:构建一个能同时接收真实嵌入向量、“假设”文本序列及其嵌入空间位置作为输入,并预测原始文本序列的系统。我们将此视为一种“学习型优化”(learned optimization) —— 以离散序列的形式在嵌入空间中逐步推进。这正是我们命名为 vec2text 的方法核心。
在对一些细节进行处理并对模型进行训练后,可得知该方法效果极佳!单次校正前向传播即可将 BLEU 分数从 30 提升到 50。该模型的优势在于天然支持递归查询:给定当前文本及其嵌入向量,可运行多个优化步骤,迭代生成“假设”文本,重新将它们嵌入,并将其作为输入反馈给模型。经过 50 步迭代和若干优化技巧,我们实现了:32 词元序列的精确还原率达 92%,BLEU 分数达到 97!(通常达到 97 的 BLEU 分数意味着近乎完美重建每个句子,可能偶尔出现标点偏差。)
未来工作方向
文本嵌入向量能够被完美反演(inverted)这一事实引出了诸多后续问题。首先,文本嵌入向量包含了固定的比特数量;当序列长度超过一定阈值时,信息必然无法完美存储于此向量中。尽管我们能复原大多数长度为 32 词元的文本,但某些嵌入模型可处理长达数千词元的文档。文本长度、嵌入维度与嵌入可逆性的关系分析将留给未来研究。
另一待解问题是:如何构建能防御反演攻击的系统。是否存在一种模型,既能有效生成有实用价值的文本嵌入,又能对原始文本进行混淆处理?
最后,我们期待该方法在其他模态中的应用前景。vec2text 的核心思想(在嵌入空间中实施迭代式优化)未使用任何文本模态专用的技巧。这是一种通过黑盒访问模型逐步还原任意固定输入信息的方法。这些理念如何应用于其他模态嵌入的反演,以及更广义的非嵌入反演方法,仍有待探索。
若需使用我们的模型反演文本嵌入,或自行开展嵌入反演实验,请访问 Github 仓库:
https://github.com/jxmorris12/vec2text
References
Inverting Visual Representations with Convolutional Networks (2015), https://arxiv.org/abs/1506.02753
Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers (2021), https://proceedings.mlr.press/v139/teterwak21a/teterwak21a.pdf
Text Embeddings Reveal (Almost) As Much As Text (2023), https://arxiv.org/abs/2310.06816
Language Model Inversion (2024), https://arxiv.org/abs/2311.13647
END
本期互动内容 🍻
❓文章揭示的文本嵌入向量可逆性(近乎完美还原 32 词元文本),是否让你对将敏感数据存储在向量数据库中感到担忧?你的公司/项目会因此重新评估使用向量数据库存储敏感文本的策略吗?
文中链接
[1]https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
[2]https://techcrunch.com/2023/04/27/pinecone-drops-100m-investment-on-750m-valuation-as-vector-database-demand-grows/
[3]https://siliconangle.com/2023/04/06/chroma-bags-18m-speed-ai-models-embedding-database/
[4]https://www.prnewswire.com/news-releases/weaviate-raises-50-million-series-b-funding-to-meet-soaring-demand-for-ai-native-vector-database-technology-301803296.html
[5]https://techcrunch.com/2023/04/19/qdrant-an-open-source-vector-database-startup-wants-to-help-ai-developers-leverage-unstructured-data/
[6]https://arxiv.org/abs/2310.06816
[7]https://openaccess.thecvf.com/content_cvpr_2016/papers/Dosovitskiy_Inverting_Visual_Representations_CVPR_2016_paper.pdf
[8]https://arxiv.org/pdf/2103.07470.pdf
[9]https://arxiv.org/abs/1806.00400
[10]https://arxiv.org/abs/2008.01777
[11]https://arxiv.org/abs/2112.09164
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://thegradient.pub/text-embedding-inversion/

AI及大模型技术分享交流群
