
构建一个能够超越有限上下文窗口的鲁棒 AI 记忆系统,需要选择性地存储重要信息、整合相关概念并在需要时检索相关细节,这模仿了人类的认知过程。

(底层机制 两阶段内存流水线,用于提取、整合和检索最突出的对话事实,从而实现可扩展的长期推理。)
几种关键技术实现方法:
- 这种方法不依赖将整个对话历史保留在固定上下文窗口内。
- 它通过专用的模块来管理突出信息,通常包括提取和更新两个阶段。
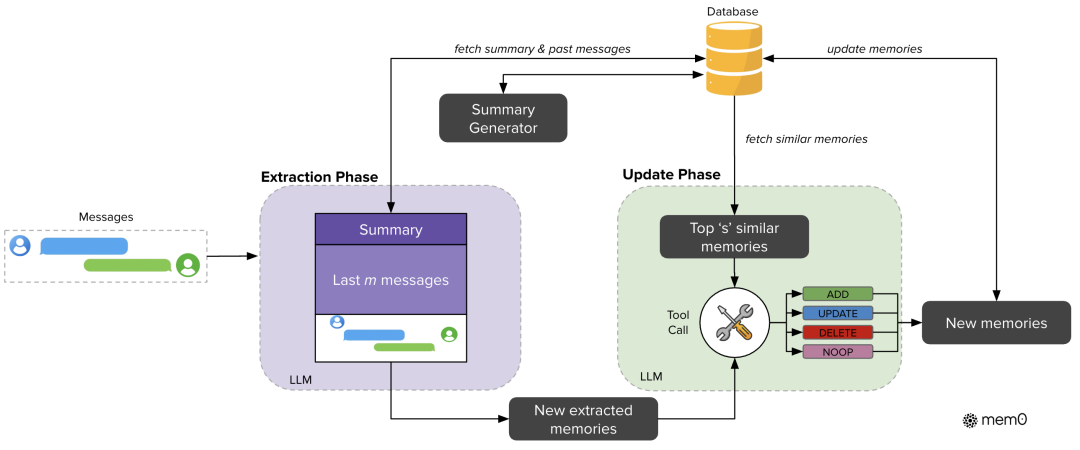
- 提取阶段:处理新的消息对(例如,用户消息和助手回复)。系统会利用会话摘要(捕捉整体语义内容)和近期消息序列(提供粒度时间上下文)作为背景信息。然后,通过 LLM 根据这些上下文来识别并提取对话中的一组突出的记忆或事实。
- 更新阶段:评估提取出的候选记忆与现有记忆。系统会检索与候选记忆语义相似的现有记忆。然后,利用 LLM 的推理能力和 Tool Call 机制(或类似的函数调用接口)来决定适当的记忆管理操作:
- ADD (添加):当没有语义等价的现有记忆时,添加新的记忆。
- UPDATE (更新):用补充信息增强现有记忆。
- DELETE (删除):移除被新信息矛盾的记忆。
- NOOP (无操作):当候选事实不需要对知识库进行修改时。
- 这种方法将完整的对话轮次编码为简洁的自然语言表示,仅捕获内存中最突出的事实,从而减少噪声并为 LLM 提供更精确的提示。
- 其优势在于通过选择性内存检索机制动态识别并仅检索最相关的信息,从而维持一致的性能,而不受会话长度影响。这种方法在单跳和多跳查询中表现出色,且通常能实现较低的搜索和总延迟以及显著降低的 Token 消耗。
- 这是一种增强上述基础架构的方法,记忆存储为有向带标签的图。
- 在这种表示中,实体作为节点(例如,人物、地点、事件),而关系作为边缘连接这些节点(例如,'lives_in', 'prefers')。
- 这种结构能够捕捉复杂的、对话元素之间的关系结构,从而更好地理解实体之间的联系。
- 提取与更新:
- 提取过程利用 LLM 将非结构化文本转换为结构化图表示。这通常包括实体提取(识别对话中的关键信息元素)和关系生成(确定实体间的语义连接)。
- 更新过程涉及冲突检测和解决机制,由 LLM 决定集成新信息时是否标记现有关系为无效。
- 这种结构支持跨互连事实的更高级推理,特别适用于需要导航复杂关系路径的查询。
- 检索机制:可以采用多种方法,例如实体中心法(识别查询中的实体,然后在图数据库中探索相关节点及边缘)和语义三元组法(编码查询向量,与文本编码的关系三元组进行匹配)。
- 底层实现可以使用图数据库,如 Neo4j。
- 这种方法在时态推理和开放领域任务中表现突出,验证了结构化关系图在捕捉时间关系和整合外部知识方面的优势。然而,构建和查询图结构可能引入适度的延迟开销相比于简单的自然语言记忆,并且可能需要更多的 Token 来表示图结构。

- 分层记忆系统:将记忆分为不同层次(如短时记忆/上下文窗口、长时记忆/外部存储),并通过机制在这些层次之间“分页”信息。
- 短期/长期记忆组件:例如,使用会话摘要作为短期记忆,将对话回合转化为事实性“观察”作为长期记忆,并结合时态事件图。
- Gisting (要点提取):将文本段落提炼成简洁的摘要,保留核心意义但减少 Token 量,并在需要时检索原始文本。
- 记忆衰减机制:模拟人类遗忘,记忆在被检索时会加强,而未使用的会随时间衰减。
- 基于笔记的记忆系统:通过互连的笔记动态构建和演化记忆,笔记包含结构化属性(关键词、描述、标签),并随新记忆的整合而更新。
- 时态知识图:专门用于管理具有时间戳信息的对话内容,以处理时间敏感的查询。
这些不同的技术实现方法在捕捉信息、表示知识和检索相关性方面各有侧重,并在性能(如准确性、延迟、Token 消耗)上表现出不同的权衡。评估这些方法的有效性通常需要专门的基准测试(如 LOCOMO) 和能够评估事实准确性和上下文适当性的指标(如 LLM-as-a-Judge),因为传统的词汇相似性指标存在局限性。
未来的研究方向则包括优化这些结构化记忆的操作以减少延迟、探索结合效率和关系表示的分层记忆架构,以及开发更复杂的记忆整合机制。
—以下为论文原始内容—
论文: https://arxiv.org/abs/2504.19413
长期记忆挑战
虽然最近的进展已经扩展了 GPT-4、Claude 3.7 Sonnet 和 Gemini 等模型中的上下文窗口,但仅仅增加窗口大小并不能完全解决长期记忆问题。现实世界的对话很少在主题上保持一致,因此很难从广泛的上下文窗口中检索相关信息。此外,更大的上下文窗口会导致计算成本增加和响应时间变慢,这使得它们在许多部署场景中不切实际。
已经提出了几种方法来解决这一挑战:
- 检索增强生成 (RAG):将对话历史存储为文档,并在需要时检索相关块。
- 记忆增强模型:创建专用的架构修改来支持持久记忆。
- 分层记忆系统:以类似于人类记忆系统的分层结构组织记忆。
然而,这些方法通常难以解决可扩展性、效率或在扩展对话中保持连贯推理能力的问题。
Mem0:以记忆为中心的架构
Mem0 是一种新颖的以记忆为中心的架构,旨在动态捕获、整合和检索正在进行的对话中的显著信息。该系统分两个主要阶段运行:
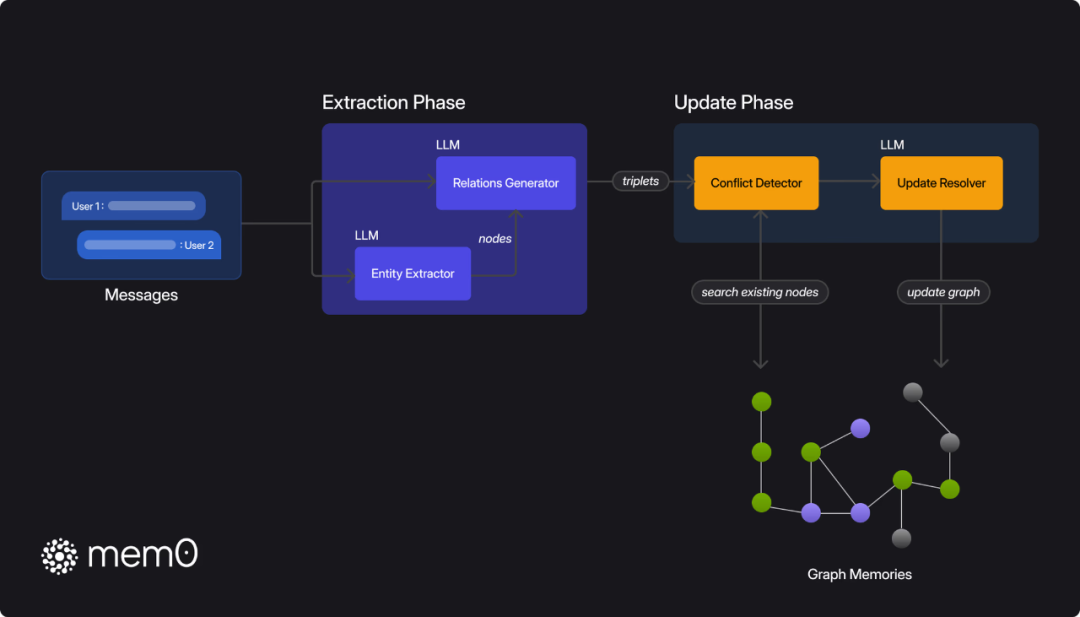
 3:Mem0 架构,展示了记忆系统的提取和更新阶段。
3:Mem0 架构,展示了记忆系统的提取和更新阶段。
提取阶段当处理新的消息对(用户消息和助手响应)时,Mem0:
-
从对话历史记录中检索对话摘要和最近的消息 -
使用基于 LLM 的提取功能来识别新交流中的显著记忆 -
考虑对话的更广泛的上下文,仅提取相关和重要的信息
提取过程旨在具有选择性,仅捕获未来交互可能需要的信息,同时过滤掉琐碎或冗余的细节。
更新阶段对于每个提取的事实,Mem0:
-
评估其与现有记忆的一致性,以保持一致性并避免冗余 -
从数据库中检索语义上相似的记忆 -
通过函数调用接口(工具调用)将这些记忆呈现给LLM -
确定适当的记忆管理操作:
-
ADD:创建新记忆 -
UPDATE:增强现有记忆 -
DELETE:删除过时或不正确的记忆 -
NOOP:无需修改
这种方法允许动态的记忆管理,随着对话的进行而演变,类似于人类如何随着时间的推移巩固和更新他们的理解。
Mem0g:基于图的记忆表示
在Mem0架构的基础上,Mem0g引入了基于图的记忆表示,以捕获复杂的关系结构。在这个增强的系统中:
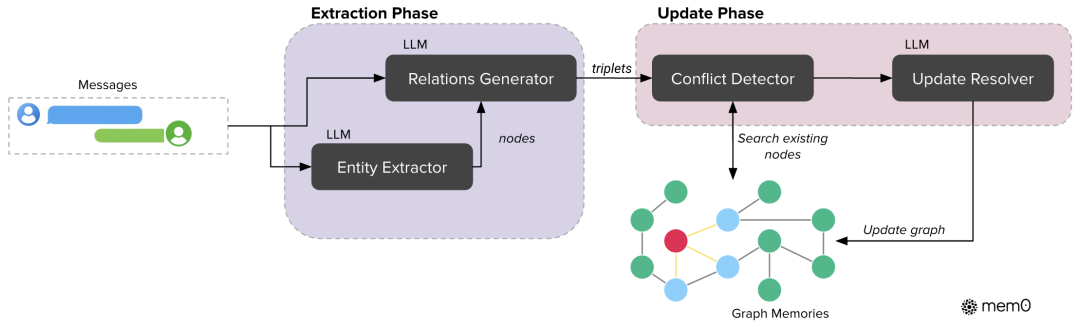 图4:具有基于图的记忆表示的Mem0g架构。
图4:具有基于图的记忆表示的Mem0g架构。
图结构记忆存储为有向标记图,具有:
-
实体作为节点(每个节点都有类型分类、嵌入向量和元数据) -
关系作为连接节点的边两阶段提取过程
- 实体提取器:从输入文本中识别关键实体及其类型
- 关系生成器:推导出实体之间有意义的连接,建立关系三元组(主语、谓语、宾语),以捕获语义结构冲突检测与解决在整合新信息时,系统:
-
识别现有图中潜在的冲突关系 -
使用基于LLM的更新解析器来确定是否应将某些关系标记为过时 -
保持知识图中的时间一致性
与平面记忆表示相比,这种结构化方法能够对复杂的、相互关联的信息进行更复杂的推理。
— END —
